
This is part 4 of a series of tutorials, in which we develop the mathematical and algorithmic underpinnings of deep neural networks from scratch and implement our own neural network library in Python, mimicing the TensorFlow API. Start with the first part: I: Computational Graphs.
- Part I: Computational Graphs
- Part II: Perceptrons
- Part III: Training criterion
- Part IV: Gradient Descent and Backpropagation
- Part V: Multi-Layer Perceptrons
- Part VI: TensorFlow
Gradient descent
Generally, if we want to find the minimum of a function, we set the derivative to zero and solve for the parameters. It turns out, however, that it is impossible to obtain a closed-form solution for $W$ and $b$. Instead, we iteratively search for a minimum using a method called gradient descent.
As a visual analogy, imagine yourself standing on a mountain and trying to find the way down. At every step, you walk into the steepest direction, since this direction is the most promising to lead you towards the bottom.

If taking steep steps seems a little dangerous to you, imagine that you are a mountain goat (which are amazing rock climbers).
Gradient descent operates in a similar way when trying to find the minimum of a function: It starts at a random location in parameter space and then iteratively reduces the error $J$ until it reaches a local minimum. At each step of the iteration, it determines the direction of steepest descent and takes a step along that direction. This process is depicted for the 1-dimensional case in the following image.
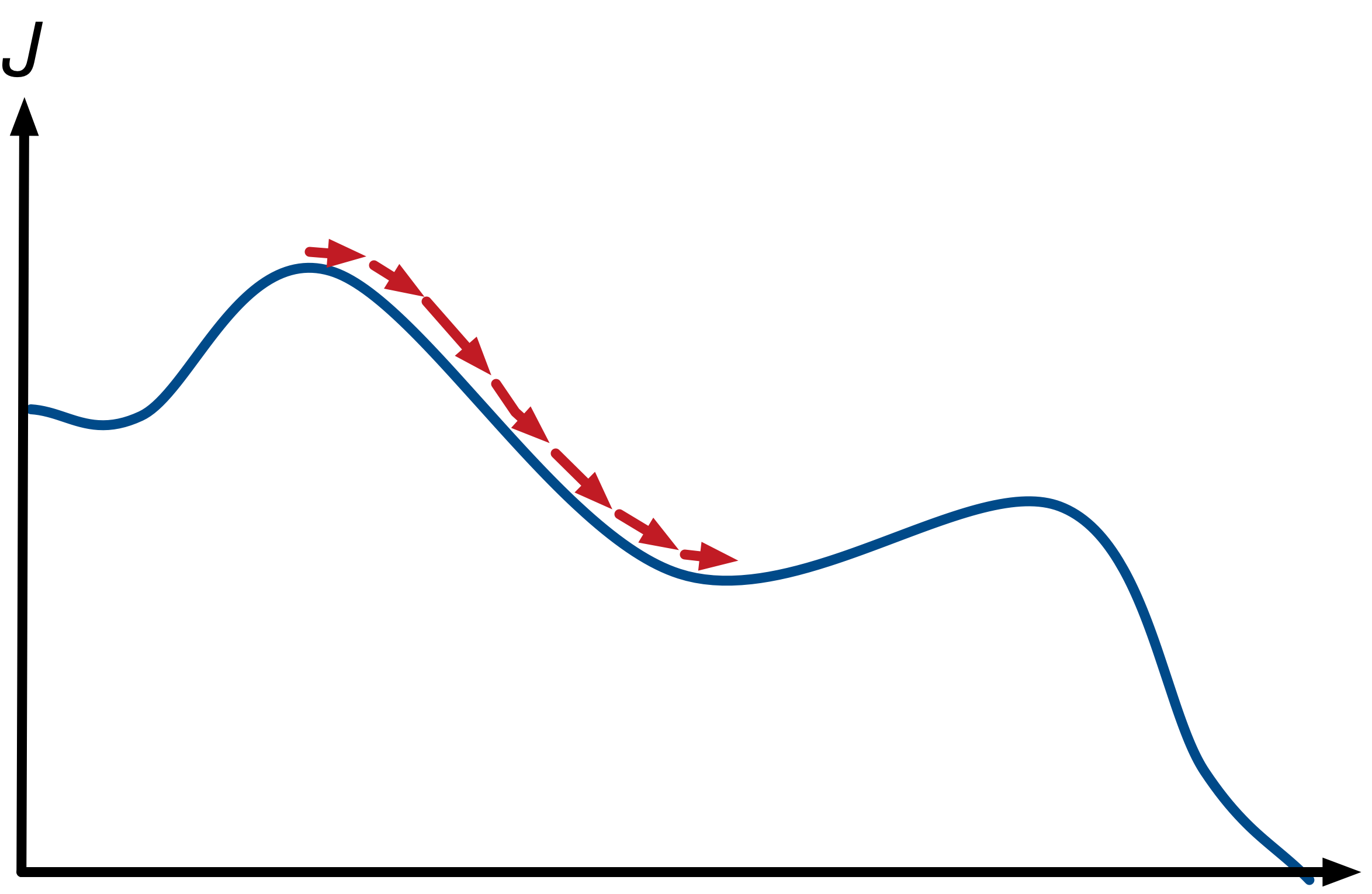
As you might remember, the direction of steepest ascent of a function at a certain point is given by the gradient at that point. Therefore, the direction of steepest descent is given by the negative of the gradient. So now we have a rough idea how to minimize $J$:
- Start with random values for $W$ and $b$
- Compute the gradients of $J$ with respect to $W$ and $b$
- Take a small step along the direction of the negative gradient
- Go back to 2
Let’s implement an operation that minimizes the value of a node using gradient descent. We require the user to specify the magnitude of the step along the gradient as a parameter called learning_rate.
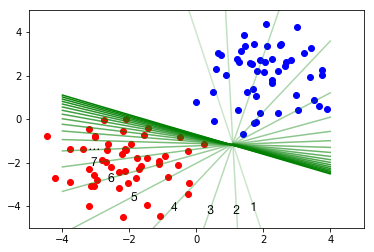
The following image depicts an example iteration of gradient descent. We start out with a random separating line (marked as 1), take a step, arrive at a slightly better line (marked as 2), take another step, and another step, and so on until we arrive at a good separating line.
Backpropagation
In our implementation of gradient descent, we have used a function compute_gradient(loss) that computes the gradient of a $loss$ operation in our computational graph with respect to the output of every other node $n$ (i.e. the direction of change for $n$ along which the loss increases the most). We now need to figure out how to compute gradients.
Consider the following computational graph:

By the chain rule, we have
$$\frac{\partial e}{\partial a} = \frac{\partial e}{\partial b} \cdot \frac{\partial b}{\partial a} = \frac{\partial e}{\partial c} \cdot \frac{\partial c}{\partial b} \cdot \frac{\partial b}{\partial a} = \frac{\partial e}{\partial d} \cdot \frac{\partial d}{\partial c} \cdot \frac{\partial c}{\partial b} \cdot \frac{\partial b}{\partial a}$$
As we can see, in order to compute the gradient of $e$ with respect to $a$, we can start at $e$ an go backwards towards $a$, computing the gradient of every node’s output with respect to its input along the way until we reach $a$. Then, we multiply them all together.
Now consider the following scenario:
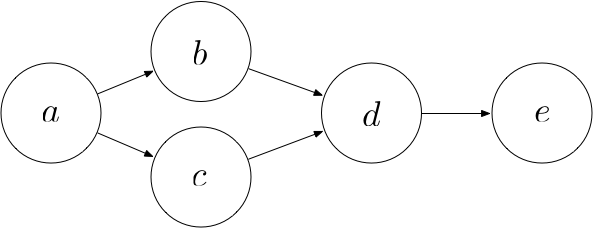
In this case, $a$ contributes to $e$ along two paths: The path $a$, $b$, $d$, $e$ and the path $a$, $c$, $d$, $e$. Hence, the total derivative of $e$ with respect to $a$ is given by:
$$
\frac{\partial e}{\partial a}
= \frac{\partial e}{\partial d} \cdot \frac{\partial d}{\partial a}
= \frac{\partial e}{\partial d} \cdot \left( \frac{\partial d}{\partial b} \cdot \frac{\partial b}{\partial a} + \frac{\partial d}{\partial c} \cdot \frac{\partial c}{\partial a} \right)
= \frac{\partial e}{\partial d} \cdot \frac{\partial d}{\partial b} \cdot \frac{\partial b}{\partial a} + \frac{\partial e}{\partial d} \cdot \frac{\partial d}{\partial c} \cdot \frac{\partial c}{\partial a}
$$
This gives us an intuition for the general algorithm that computes the gradient of the loss with respect to another node: We perform a backwards breadth-first search starting from the loss node. At each node $n$ that we visit, we compute the gradient of the loss with respect do $n$’s output by doing the following for each of $n$’s consumers $c$:
- retrieve the gradient $G$ of the loss with respect to the output of $c$
- multiply $G$ by the gradient of $c$’s output with respect to $n$’s output
And then we sum those gradients over all consumers.
As a prerequisite to implementing backpropagation, we need to specify a function for each operation that computes the gradients with respect to the inputs of that operation, given the gradients with respect to the output. Let’s define a decorator @RegisterGradient(operation_name) for this purpose:
Now assume that our _gradient_registry dictionary is already filled with gradient computation functions for all of our operations. We can now implement backpropagation:
Gradient of each operation
For each of our operations, we now need to define a function that turns a gradient of the loss with respect to the operation’s output into a list of gradients of the loss with respect to each of the operation’s inputs. Computing a gradient with respect to a matrix can be somewhat tedious. Therefore, the details have been omitted and I just present the results. You may skip this section and still understand the overall picture.
If you want to comprehend how to arrive at the results, the general approach is as follows:
- Find the partial derivative of each output value with respect to each input value (this can be a tensor of a rank greater than 2, i.e. neither scalar nor vector nor matrix, involving a lot of summations)
- Compute the gradient of the loss with respect to the node’s inputs given a gradient with respect to the node’s output by applying the chain rule. This is now a tensor of the same shape as the input tensor, so if the input is a matrix, the result is also a matrix
- Rewrite this result as a sequence of matrix operations in order to compute it efficiently. This step can be somewhat tricky.
Gradient for negative
Given a gradient $G$ with respect to $-x$, the gradient with respect to $x$ is given by $-G$.
Gradient for log
Given a gradient $G$ with respect to $log(x)$, the gradient with respect to $x$ is given by $\frac{G}{x}$.
Gradient for sigmoid
Given a gradient $G$ with respect to $\sigma(a)$, the gradient with respect to $a$ is given by $G \cdot \sigma(a) \cdot \sigma(1-a)$.
Gradient for multiply
Given a gradient $G$ with respect to $A \odot B$, the gradient with respect to $A$ is given by $G \odot B$ and the gradient with respect to $B$ is given by $G \odot A$.
Gradient for matmul
Given a gradient $G$ with respect to $AB$, the gradient with respect to $A$ is given by $GB^T$ and the gradient with respect to $B$ is given by $A^TG$.
Gradient for add
Given a gradient $G$ with respect to $a + b$, the gradient with respect to $a$ is given by $G$ and the gradient with respect to $b$ is also given by $G$, provided that $a$ and $b$ are of the same shape. If $a$ and $b$ are of different shapes, e.g. one matrix $a$ with 100 rows and one row vector $b$, we assume that $b$ is added to each row of $a$. In this case, the gradient computation is a little more involved, but I will not spell out the details here.
Gradient for reduce_sum
Given a gradient $G$ with respect to the output of reduce_sum, the gradient with respect to the input $A$ is given by repeating $G$ along the specified axis.
Gradient for softmax
Example
Let’s now test our implementation to determine the optimal weights for our perceptron.
Notice that we started out with a rather high loss and incrementally reduced it. Let’s plot the final line to check that it is a good separator:
If you have any questions, feel free to leave a comment. Otherwise, continue with the next part: V: Multi-Layer Perceptrons
Good job explaining this, Daniel!
This is cool.
Would really like to see what exactly is being calculated when you say gradient of J w.r.t W and b. Like you have the chain rule diagram showing the nodes a,b,c,d,e, I think if you could actually write the nodes J,W,X,B appropriate to the graph and show what exact gradient is calculated that would make this way more understandable for me. Thanks for the amazing post !
Good point. The reason that I use letters is the fact that the algorithm is independent of the computational graph that we use to feed it, so it could be used to optimize any function J with respect to any input nodes, regardless of how they contribute to J. But you’re right that it would be helpful to apply it to the examples that we encountered already. I grant that the explanation of backpropagation is a little short. I’ll probably work on an update in the future.
For now, imagine every input matrix to every node. For every individual input matrix, we compute a matrix of the same shape as that input matrix. The entry at (i, j) in that matrix tells us how J changes as a function of the entry (i, j) in the input matrix, that is, dJ / dM(i, j).
Take a look at the final perceptron graph from lesson 2. Here, we would first compute dJ / dSigma, then dJ/(XW+b), then dJ/db and dJ/dXW, then dJ/dW and dJ/dX. The shapes of these derivatives correspond to the shape of what’s in the denominator.
I hope this helps.
Hi Daniel,
Your explanation helped and as I mentioned earlier I think would understand the derivative process more clearly when i saw the math for each step. As you mention that it gets tedious, can you recommend a source for where one can find the relevant steps?
I think it also brings to light the advancements in symbolic algebra that made neural networks popular again.
First of all, it is important to realize that backpropagation is a meta-algorithm that is independent of the individual operations and how their gradients are computed. It only presupposes that there is a method for each operation that turns a gradient with respect to a node’s output into gradients with respect to the node’s inputs.
Thus, you should first try to understand backpropagation as a meta-algorithm on general computational graphs without considering any neural network stuff whatsoever.
Once you are at that point, you can read the section “Gradient of each operation” that defines these functions. True, I haven’t developed the math for each operation. Maybe start with the gradient computation for “log” and “multiply”. These are the easier ones. Once you understand how they come about, you should be able to work out the math for the other gradients yourself. It’s a nice exercise. And I’ll admit that I don’t know them anymore, I worked them out once on paper and decided that the computations are too tedious to include in the blog.
Understanding the principles is, however, more important than the individual computations – and I would say that it is sufficient to become a good neural network engineer. You only derive them once, code them and then you’ll probably never think about them again in your entire life.
Thanks for this tutorial, it’s pitched at just the right level and is exactly what I was looking for 🙂 I did find this section a bit difficult to follow though, because I was initially confused why the backwards propagation for a given node was looking at the derivative of the consumer rather than at its inputs. I found it quite helpful to focus on one step first and keeping the loss in mind e.g. dl/dd = dl/de * de/dd thus when stepping from e to d, and knowing dl/de already, you need to evaluate de/dd which is the consumer operation from the point of view of d. Once I got my head around that, the rest became clear.
One question though – intuitively I would have expected the gradient function to have been a method of the Operation so that it is defined and accessed in the same way as the mathematical operation itself. Is there a particular reason for why this code (and presumably tensorflow) uses the registry and decorator to bind them instead?
The reason I did it this way is because TensorFlow does it this way. I do not know what their reason is, actually. I would have preferred to put it into the operation class.
Maybe this move allows experts to improve stability or speed as shown in Goodfellow’s book:
the specialized approach also has the benefit of allowing customized
back-propagation rules to be developed for each operation, allowing the developer
to improve speed or stability in non-obvious ways.
Note that Ian Goodfellow was a student of Yoshua Bengio whose team developed Theano.
why is that it is impossible to obtain a closed-form solution for WW and bb using the closed form. don’t we have the derivative chain figured out , then set it to zero?
Yes, you can write it down and set it to zero, but it is impossible to solve this equation for the weights.
When I follow the tutorial’s code, in the example part I get this error.
Step: 0 Loss: 65.7448384796
—————————————————————————
in ()
KeyError Traceback (most recent call last)
35 if step % 10 == 0:
36 print(“Step:”, step, ” Loss:”, J_value)
—> 37 session.run(minimization_op, feed_dict)
38
39 # Print final result
13 else:
14 node.inputs = [input_node.output for input_node in node.input_nodes]
—> 15 node.output = node.compute(*node.inputs)
16
17 if type(node.output) == list:
11 def compute(self):
12 # Compute gradients
—> 13 grad_table = compute_gradients(loss)
14
15 # Iterate all variables
22
23 consumer_op_type = consumer.__class__
—> 24 bprop = _gradient_registry[consumer_op_type]
25
26 lossgrads_wrt_consumer_inputs = bprop(consumer, lossgrad_wrt_consumer_output)
KeyError:
Thanks for mentioning! The softmax gradient function was missing from the blog post. I’ve added it now. So copy the gradient for softmax into your code as well, then it should work.
A bit of a noobie question.
When defining the class Register Gradient the __call__ is defined as follows:
def __call__(self, f):
“””Registers the function `f` as gradient function for `op_type`.”””
_gradient_registry[self._op_type] = f
return f
why do we return f if f is the input of __call__?
The are decorators which accept arguments in the constructor, say ‘__init__(self, *args)’ and not the function to be decorated ‘__init__(self, f)’. In this case, the function will be passed to the __call__(self, f) method of the class during decoration process. Here the decoration gets done by the __call__ method rather than the constructor.
The __call__(self, f) will accept f – the function to be decorated, do some decoration and return a decorated function. But in the RegisterGradient class, there’s no explicit decoration done, except to update a dictionary. Thus it is essential to return the same function. Since all method/function decorators need to return a function, the same function is returned (except in the case of constructors where objects are created and returned as functions).
Reference: http://python-3-patterns-idioms-test.readthedocs.io/en/latest/PythonDecorators.html
Having another issue, this time I cannot seem to debug.
Error message:
———————————————————————————–
File “C:\ProgramData\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py”, line 880, in runfile
execfile(filename, namespace)
File “C:\ProgramData\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py”, line 102, in execfile
exec(compile(f.read(), filename, ‘exec’), namespace)
File “C:/Users/MSI Gaming/Documents/Python/Deep_ideas_deep_learning/simple_back_prop.py”, line 5, in
import gradient
File “C:\Users\MSI Gaming\Documents\Python\Deep_ideas_deep_learning\gradient.py”, line 58, in
@register_grad(“negative”)
File “C:\Users\MSI Gaming\Documents\Python\Deep_ideas_deep_learning\gradient.py”, line 43, in __init__
self._op_type = eval(op_type) # ?????
File ““, line 1, in
NameError: name ‘negative’ is not defined
————————————————————–
Code regarding negative, and class registers:
————————————————————————————
grad_reg = {} # A dictionary that maps operations to their grad function
class register_grad:
def __init__(self, op_type): # create new decorator
self._op_type = eval(op_type) # ?????
“”” __call__ allows the instance of the class to be called as function “””
def __call__(self, f): # registers f as the gradient function for the operation
grad_reg[self._op_type] = f # insert value for the key
return f # why need to return?
“”” Gradients for the Operations
chain rule the gradients i.e. d/dx = d/dy(x) * dy(x)/dx
i.e. takes in grad for output, returns grad for input
The functions define the __call__ of register_grad class “””
@register_grad(“negative”)
def negative_grad(op, grad): # op is the negative operation
return -grad # Given grad wrt -x, grad wrt x = -grad
————————————————————————————
– I have a run file for the test example (simple_back_prop.py: last two techio boxes on this page, example + plotting).
– This imports: the operations.py file (first couple of lessons, all class functions incl “negative”, and the gradient.py file (most of this lesson)
– Lessons up until now run fine.
I should add tried a direct copy and paste of all code on this lesson into a single file.
Get the same error (although this time for the “multiply” operation)
I import: “numpy as np” and “operations” (file with classes from first lesson + sigmoid and softmax from second lesson).
I have 2 main questions, first is what is the value of grediant(G) fed at the output node? is it Identity Tensor?
and the second question is how for Y(m,p) = A(m,n) * X(n,p), dY/dA = X_Transposed and vice versa? the dimensions may not match either.
Can you explain how for Y = AX, the local derivatives , del Y/ del X = A_transpose and vice verse? I’m trying to find resource on vector/matrix calculus but there isn’t many at all.
I have 2 main questions, first is what is the value of grediant(G) fed at the output node? is it Identity Tensor?
and the second question is how for Y(m,p) = A(m,n) * X(n,p), dY/dA = X_Transposed and vice versa? the dimensions may not match either.
Great series! The only question that I have is with regard to the registration of the gradient functions. I don’t see in your example where it is the these function are executed. I see that compute_gradients() utilizes the registry, but I’m trying to figure out where the registry is initialized. What am I missing?
Never mind… Since the decorator code runs when the decorated function is defined, there is no need to explicitly initiate the registry.
Excellent article! Just a little comment on how the gradient of matmul can be obtained if useful for anyone.
$K(A,B):=F(AB)$
Let $K(A,B):=F(AB)$, then $\partial_A K(H) = \partial F|_{AB}(HB)=tr(G^\top HB) = tr(BG^\top H)$, showing that the gradient wrt $A$ is actually $(BG^\top)^\top=G B^\top$.
Thank you!