
This is part 3 of a series of tutorials, in which we develop the mathematical and algorithmic underpinnings of deep neural networks from scratch and implement our own neural network library in Python, mimicing the TensorFlow API. Start with the first part: I: Computational Graphs.
- Part I: Computational Graphs
- Part II: Perceptrons
- Part III: Training criterion
- Part IV: Gradient Descent and Backpropagation
- Part V: Multi-Layer Perceptrons
- Part VI: TensorFlow
Training criterion
Great, so now we are able to classify points using a linear classifier and compute the probability that the point belongs to a certain class, provided that we know the appropriate parameters for the weight matrix $W$ and bias $b$. The natural question that arises is how to come up with appropriate values for these. In the red/blue example, we just looked at the training points and guessed a line that nicely separated the training points. But generally we do not want to specify the separating line by hand. Rather, we just want to supply the training points to the computer and let it come up with a good separating line on its own. But how do we judge whether a separating line is good or bad?
The misclassification rate
Ideally, we want to find a line that makes as few errors as possible. For every point $x$ and class $c(x)$ drawn from the true but unknown data-generating distribution $p_\text{data}(x, c(x))$, we want to minimize the probability that our perceptron classifies it incorrectly – the probability of misclassification:
$$\underset{W, b}{\text{argmin}} p(\hat{c}(x) \neq c(x) \mid x, c(x) \, \tilde{} \, p_\text{data} )$$
Generally, we do not know the data-generating distribution $p_\text{data}$, so it is impossible to compute the exact probability of misclassification. Instead, we are given a finite list of $N$ training points consisting of the values of $x$ with their corresponding classes. In the following, we represent the list of training points as a matrix $X \in \mathbb{R}^{N \times d}$ where each row corresponds to one training point and each column to one dimension of the input space. Moreover, we represent the true classes as a matrix $c \in \mathbb{R}^{N \times C}$ where $c_{i, j} = 1$ if the $i$-th training sample has class $j$. Similarly, we represent the predicted classes as a matrix $\hat{c} \in \mathbb{R}^{N \times C}$ where $\hat{c}_{i, j} = 1$ if the $i$-th training sample has a predicted class $j$. Finally, we represent the output probabilities of our model as a matrix $p \in \mathbb{R}^{N \times C}$ where $p_{i, j}$ contains the probability that the $i$-th training sample belongs to the j-th class.
We could use the training data to find a classifier that minimizes the misclassification rate on the training samples:
$$
\underset{W, b}{\text{argmin}} \frac{1}{N} \sum_{i = 1}^N I(\hat{c}_i \neq c_i)
$$
However, it turns out that finding a linear classifier that minimizes the misclassification rate is an intractable problem, i.e. its computational complexity is exponential in the number of input dimensions, rendering it unpractical. Moreover, even if we have found a classifier that minimizes the misclassification rate on the training samples, it might be possible to make the classifier more robust to unseen samples by pushing the classes further apart, even if this does not reduce the misclassification rate on the training samples.
Maximum likelihood estimation
An alternative is to use maximum likelihood estimation, where we try to find the parameters that maximize the probability of the training data:
\underset{W, b}{\text{argmax}} p(\hat{c} = c) \\
\end{align}\begin{align}
= \underset{W, b}{\text{argmax}} \prod_{i=1}^N p(\hat{c}_i = c_i) \\
\end{align}\begin{align}
= \underset{W, b}{\text{argmax}} \prod_{i=1}^N \prod_{j=1}^C p_{i, j}^{I(c_i = j)} \\
\end{align}\begin{align}
= \underset{W, b}{\text{argmax}} \prod_{i=1}^N \prod_{j=1}^C p_{i, j}^{c_{i, j}} \\
\end{align}\begin{align}
= \underset{W, b}{\text{argmax}} log \prod_{i=1}^N \prod_{j=1}^C p_{i, j}^{c_{i, j}} \\
\end{align}\begin{align}
= \underset{W, b}{\text{argmax}} \sum_{i=1}^N \sum_{j=1}^C c_{i, j} \cdot log \, p_{i, j} \\
\end{align}\begin{align}
= \underset{W, b}{\text{argmin}} – \sum_{i=1}^N \sum_{j=1}^C c_{i, j} \cdot log \, p_{i, j} \\
\end{align}\begin{align}
= \underset{W, b}{\text{argmin}} J
\end{align}
We refer to $J = – \sum_{i=1}^N \sum_{j=1}^C c_{i, j} \cdot log \, p_{i, j}$ as the cross-entropy loss. We want to minimize $J$.
We can view $J$ as yet another operation in our computational graph that takes the input data $X$, the true classes $c$ and our predicted probabilities $p$ (which are the output of the $\sigma$ operation) as input and computes a real number designating the loss:
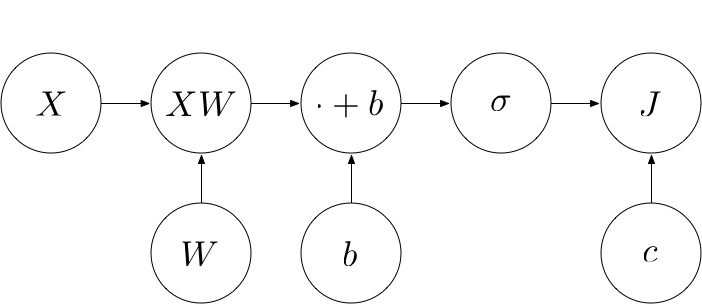
Building an operation that computes $J$
We can build up $J$ from various more primitive operations. Using the element-wise matrix multiplication $\odot$, we can rewrite $J$ as follows:
$$
– \sum_{i=1}^N \sum_{j=1}^C (c \odot log \, p)_{i, j}
$$
Going from the inside out, we can see that we need to implement the following operations:
- $log$: The element-wise logarithm of a matrix or vector
- $\odot$: The element-wise product of two matrices
- $\sum_{j=1}^C$: Sum over the columns of a matrix
- $\sum_{i=1}^N$: Sum over the rows of a matrix
- $-$: Taking the negative
Let’s implement these operations.
log
This computes the element-wise logarithm of a tensor.
multiply / $\odot$
This computes the element-wise product of two tensors of the same shape.
reduce_sum
We’ll implement the summation over rows, columns, etc. in a single operation where we specify an axis. This way, we can use the same method for all types of summations. For example, axis = 0 sums over the rows, axis = 1 sums over the columns, etc. This is exactly what numpy.sum does.
negative
This computes the element-wise negative of a tensor.
Putting it all together
Using these operations, we can now compute $J = – \sum_{i=1}^N \sum_{j=1}^C (c \odot log \, p)_{i, j}
$ as follows:
J = negative(reduce_sum(reduce_sum(multiply(c, log(p)), axis=1)))Example
Let’s now compute the loss of our red/blue perceptron.
If you have any questions, feel free to leave a comment. Otherwise, continue with the next part: IV: Gradient Descent and Backpropagation
can you please give a noob tutorial for understand a little the tensor flow too? thanks 🙂
If you follow the blog post, you will understand how to use TensorFlow as well. Just ignore the implementations of the library functions, then it’s like a TensorFlow tutorial.
Bravo! Great explanation of relationship between MLE and X-Entropy. Thanks.
[[1, 0]] * len(blue_points)
+ [[0, 1]] * len(red_points),
why is len function here? what is the use of it?
We need an array of the same size as the set of points. It has to be filled with [1, 0] for every blue point and [0, 1] for every red point. [[1, 0]] * len(blue_points) just creates an array [[1, 0], [1, 0], [1, 0], …] containing the class for all the points that should be blue. The same for the red points.
Hi, I’m a little bit confused by the arrow in a computational graph that goes directly from X to J. As far as I see from the final equation for J, the direct dependency is only on c and sigma (p in the equation). Is that arrow in a graph redundant?
You’re totally right. I’ll fix this asap. Thanks for noticing!
I also noticed it and find It’s still there.
Thanks for the reminder. “Asap” implied “when I’m done with my exams”, which is now :D. It’s fixed now.
hi Daniel, is there a way to write J naturally, i.e. J = -np.sum(np.sum(c*np.log(p), axis=1)), instead of creating negative, add, minus, multiply… class? thanks for your tutorial!
Hello Sam!
It is entirely possible to create a single operation class for the cross-entropy loss instead of nesting the various operations inside each other, using the computation that you wrote down. There are three reasons why this is not done in the tutorial:
– Introducing the primitive operations pays off as it allows for flexible reuse when a slight change is made to the loss function
– In the following section, you need to define gradients for each operation. It is easier to define gradients for the primitive operations and let the algorithm take care of computing the gradient for the complex operation
– TensorFlow also does it like this (or at least they did at the time the tutorial was written)
Best,
Daniel